为什么Redis快?
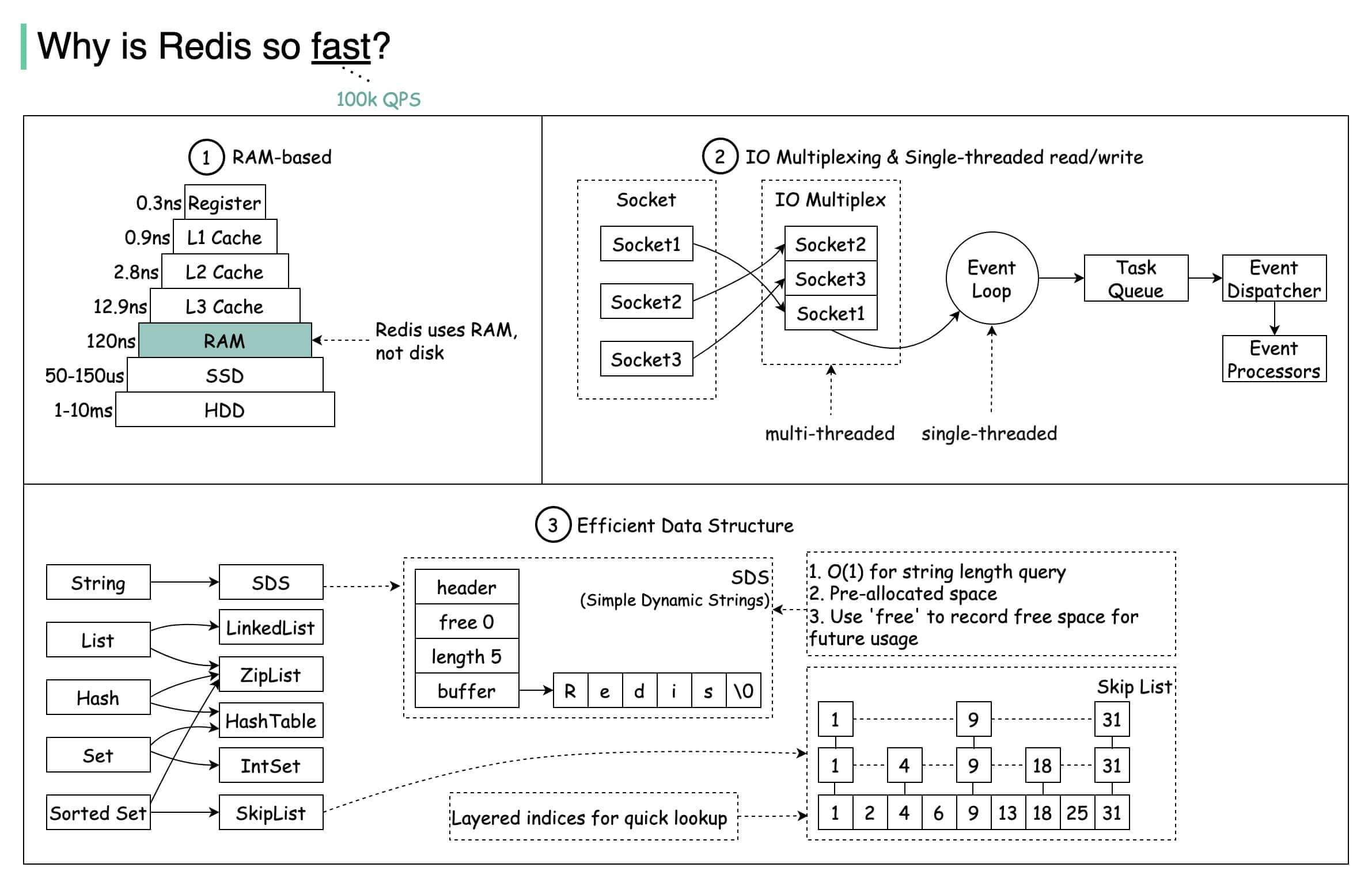
1.完全基于内存实现
优点是快, 缺点是内存的数据会断电丢失. 不过redis提供了持久化的策略方案RDB和AOF.
为什么基于内存实现就快呢?
内存快是相对于硬盘来说的,因为内存的设计以及直接与CPU总线连接. 而硬盘作为外存是需要中间计算转换block访问的,所以比内存慢是自然的.
比内存更快的存储还有上一级缓存和寄存器.
要做到快,就要做到时刻准备(持续通电), 直接读取(不需要中间转换), 距离CPU更近(光的物理传输性能)
参考: https://www.ruanyifeng.com/blog/2013/10/register.html
2.优秀的数据结构设计
良好的数据结构设计可以更好的面向于用户的使用场景,针对用户最频繁的操作做出相应的优化. 虽然也有了一些局部的取舍,但是在整体上面是非常值得的.
SDS: Simple Dynamic String(简单动态字符串). 相比于普通的字符串设计, SDS在结构中保存了len和free两个值,前者可以以O(1)的时间获取到字符串长度. 后者则是在扩容是提前分配, 在缩容时惰性释放, 减少字符串内容变更需要扩容缩容时的内存重新分配次数.
Hash Table: 哈希表作为Hash和Set的底层数据结构, 其主要的特点是通过冗余了一个hash table来方便的进行扩容和缩容, 并且实现了渐进式的refresh过程
SkipList:先直接引用一下作者antirez的原文回答:
\1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
\2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
\3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
作者在内存使用效率, 常见使用场景上的效率, 实现复杂度上与b树都做了对比. 认为跳表在redis中更适合.
LinkedList, ZipList, IntSet在我看来对比常见的实现方案没有特别值得讲的地方.
3. 单线程的网络处理模型
通过非阻塞IO和多路复用(multiplexing), redis的事件处理只有单个线程, 单个线程的好处是避免了多线程下的各种避免数据冲突而额外引入的开销(例如锁). 不过redis会在IO处理以及一些不影响主线程的事件中(例如大型键的删除)支持多线程处理.
至于为什么采用单线程: 作者的想法是主要性能不再cpu而是网络IO,单线程也够用,并且单线程实现简单避免了各种数据冲突情况.
Redis的内存管理
内存管理主要处理2个情况:
- 内存不足时对数据的处理策略
- 过期键的删除策略
对于内存不足时的情况,redis提供了8种策略:
- volatile-lru(least recently used):从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。
- allkeys-lru(least recently used):从数据集中移除最近最少使用的数据淘汰。
- allkeys-random:从数据集中任意选择数据淘汰。
- no-eviction(默认内存淘汰策略):禁止驱逐数据,当内存不足以容纳新写入数据时,新写入操作会报错。
- volatile-lfu(least frequently used):从已设置过期时间的数据集中挑选最不经常使用的数据淘汰。
- allkeys-lfu(least frequently used):从数据集中移除最不经常使用的数据淘汰。
对于过期键的删除:
同样是效率和性能的取舍, 最高效率肯定是不间断的检查所有设置了过期时间的key, 但这样性能在某些时刻同样很差(比如一大批键同一时刻过期). 降低检查的频率和检查对象的个数可以平衡,但是还不够.因为这样不能保证过期的键都被删除了, 于是引入了惰性删除,即在获取键时检查键是否过期, 来作为一个弥补和平衡的措施保证功能正常.