最近工作中发现生产环境里一个sql慢的有点离谱,整整跑了近750s,12.5分钟! 还好是一个后台任务,对时间要求不是很大. 但是这么慢还是引起了我的好奇心, 所以本文深入研究了一下.
1
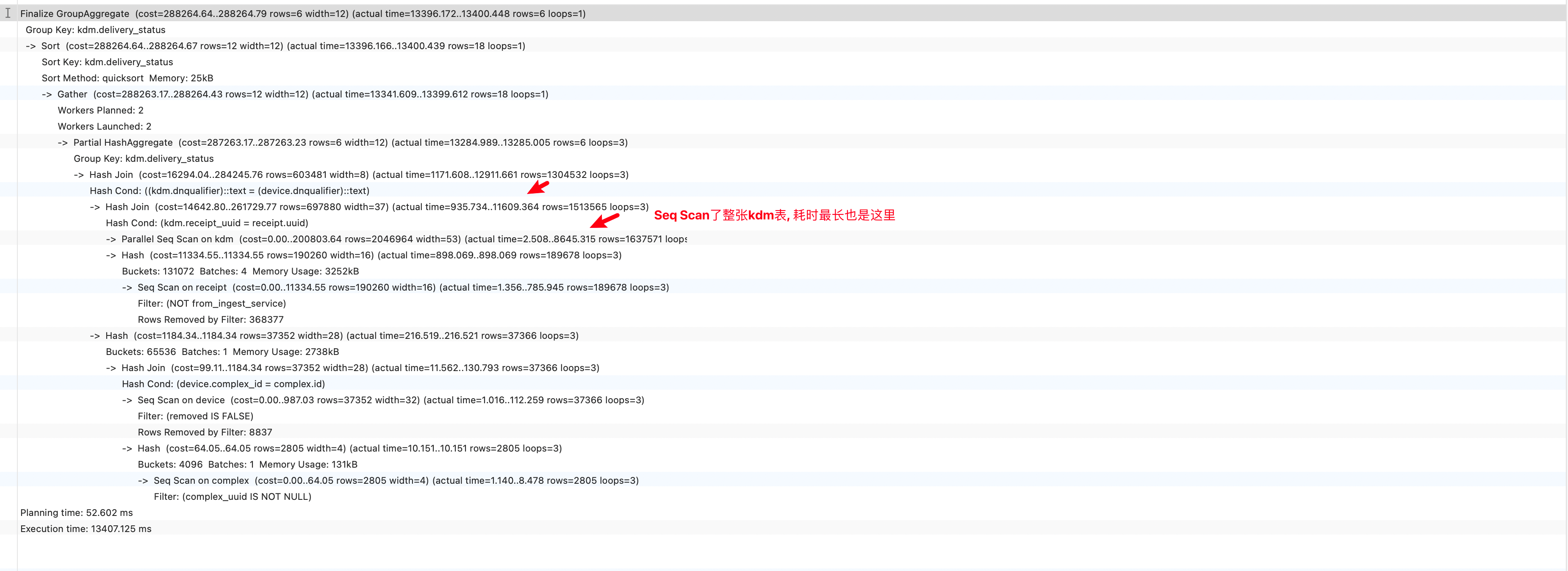
2023-09-12 02:03:40 UTC:172.31.110.153(46482):kdmts@kdmts:[32237]:LOG: duration: 747989.755 ms statement: SELECT count(kdm.kdm.id) AS count, kdm.kdm.delivery_status AS kdm_kdm_delivery_status FROM kdm.kdm JOIN flm.device ON flm.device.dnqualifier = kdm.kdm.dnqualifier JOIN shared.complex ON shared.complex.id = flm.device.complex_id JOIN kdm.receipt ON kdm.receipt.uuid = kdm.kdm.receipt_uuid WHERE flm.device.removed IS false AND shared.complex.complex_uuid IS NOT NULL AND kdm.receipt.from_ingest_service = false GROUP BY kdm.kdm.delivery_status
排查explain结果
首先在本地数据库执行
EXPLAIN ( ANALYZE, timing ) {sql}
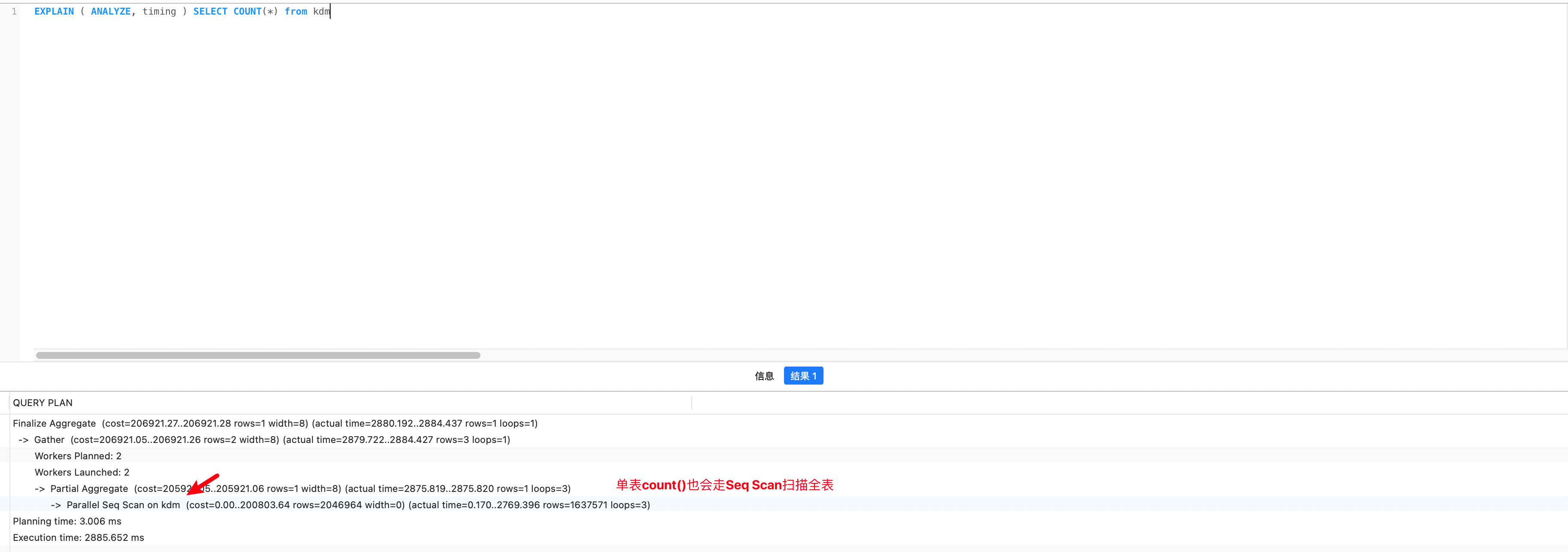
尝试单表的count(),发现仍然会扫描全表
为什么一定要触发全表扫描呢? 在我的印象里Mysql似乎是不需要的. 我查找了些资料来说明这个问题.
数据库的count()实现
会把表的总行数记录到一个单独的数据值中,这样每次查询只要读取这个值就行了,这样不就不用每次都扫描全表了吗?
是的,Mysql的MyISAM引擎的确就是这么实现的,但这里的前提是数据不支持事务操作. 并且, 这种方式只解决了获取全表数据总数的情况, 当需要增加where条件判断时,仍然需要去扫描整个表.
在支持事务的引擎中如何去实现count()呢?
由于事务普遍使用Repeated Read(可重复读)的隔离级别, 而此隔离级别下,会使用MVCC(多版本控制)来实现事务的特性. 但在多个事务并行的情况下,count(*)很可能会返回不同的结果.因此没法像MyISAM引擎那样预存一个count()的结果值, 只能扫描所有数据行. 但是, 一个优化策略是会在可能的情况下,不去扫描原本数据行,而是扫描索引, 找到最小的索引树来扫描,相比扫描完整的数据行来说,会减少一些时间. Mysql的确是这么做的,但是为什么PostgreSQL不走索引呢? 这里主要是因为PostgreSQL的MVCC实现里引入了live_tuple和dead_tuple, 在每次update,delete的时候会更新这个元祖数据, 但是并不会把这个数据引入到索引中, 所以扫描索引就不能获取真正正确的值. 只有在经过vacuum清理了tuple,才能拿到正确的值.
count(1),count(*),count(id)的区别
Mysql的count(*)据说底层有优化,但PostgreSQL的count(1)和count(*)是一样的
count本身都是对参数的判断是否为null,
执行效率上:count(非主键字段) < count(主键) < count(1) ≈ count(*) (Mysql)
如何解决
对于我遇到的实际生产上的需求, 在提高count()的效率方面能做的有限,比如增加数据库的内存配置, 尽可能的将一些操作再内存操作而不是磁盘. 但这并不是一个效率的解决办法. 幸运的是,统计的需求一般对时效性要求不高, 所以可以将这类任务都放到后台任务去做,配置一个合理的任务超时时间即可.